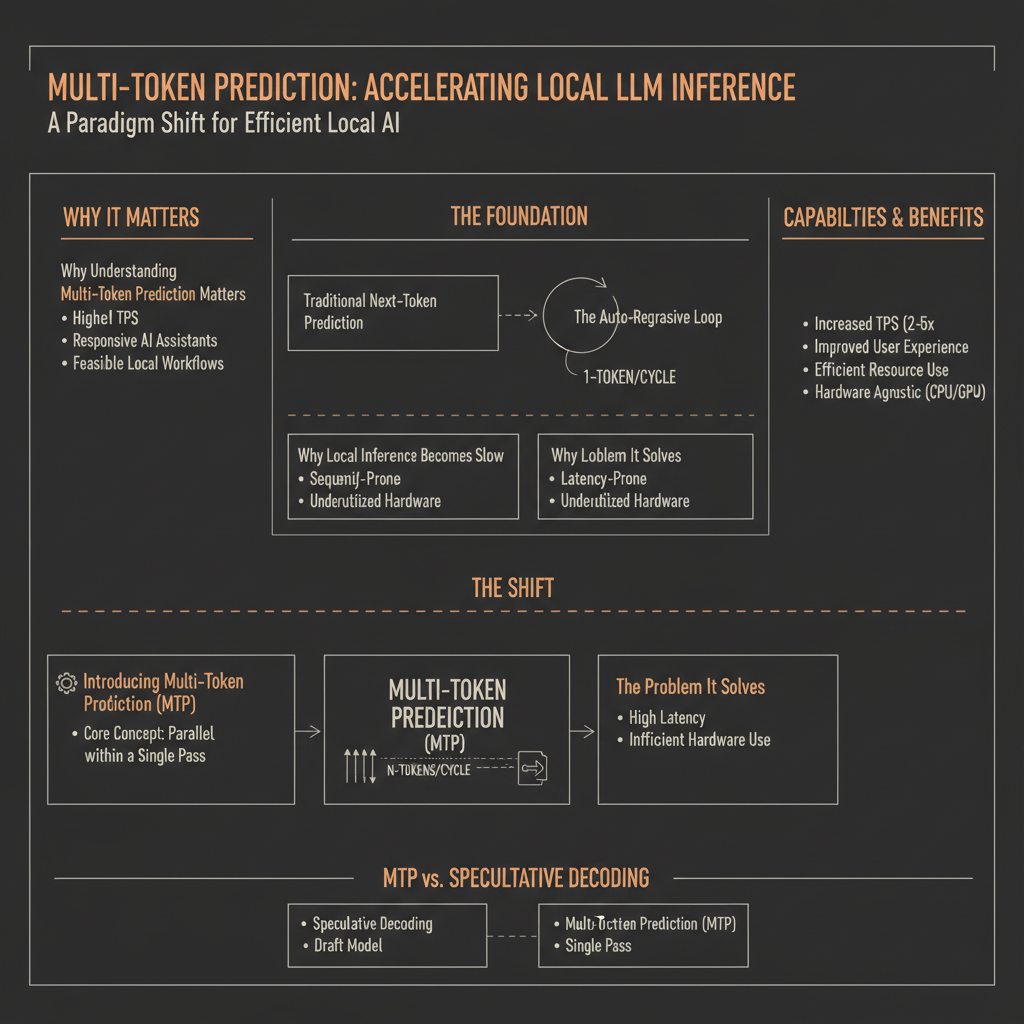
The promise of large language models (LLMs) running efficiently on local hardware has long been tempered by the reality of slow, token-by-token generation. Imagine typing a prompt into a local LLM, and waiting several seconds for just a few words to appear. This frustrating latency is a significant barrier to integrating powerful AI into everyday local workflows. Multi-Token Prediction (MTP) is an architectural advancement designed to fundamentally address this bottleneck, moving beyond the traditional one-token-at-a-time generation loop.
Why Understanding Multi-Token Prediction Matters
Understanding MTP is crucial because it represents a shift in how LLMs generate text. For engineers, it explains why certain models like Qwen and Gemma can achieve significantly higher tokens-per-second (TPS) on local hardware without resorting to complex speculative decoding setups. For users, it highlights the architectural innovations that make local AI assistants, code generators, and creative tools feel more responsive and practical. As LLMs become integrated into more local applications, the efficiency gains from MTP will define the user experience and the feasibility of running powerful models offline.
The Foundation: Traditional Next-Token Prediction
At its core, every modern LLM operates on an auto-regressive principle. This means it predicts the next token based on all the previous tokens it has generated or seen. This process is inherently sequential.
The Auto-Regressive Loop
When you prompt an LLM, the following steps occur repeatedly:
- Input Tokenization: Your prompt is broken down into a sequence of numerical tokens.
- Initial Forward Pass: The LLM processes the entire input sequence through its transformer layers (attention mechanisms, feed-forward networks).
- Logit Output: The final layer outputs a probability distribution (logits) over the entire vocabulary for the next token.
- Token Sampling: A token is sampled from this distribution (e.g., greedy sampling for the most probable, or nucleus sampling for more creativity).
- Append and Repeat: The newly generated token is appended to the input sequence, and the entire process (steps 2-4) repeats.
Why Local Inference Becomes Slow
This “one token at a time” loop is the primary culprit for slow local inference:
- Sequential Bottleneck: Each token requires a full forward pass through the entire model. This means that to generate 100 tokens, the model must execute 100 separate forward passes.
- GPU/CPU Bound: Even with powerful hardware, the repeated loading of model weights and computations for each pass introduces latency.
- Memory Bandwidth: Model weights and KV cache entries must be accessed repeatedly from VRAM (or RAM for CPU inference). Each forward pass involves fetching these.
- KV Cache Growth: The Key-Value (KV) cache stores intermediate attention states for previous tokens, avoiding recomputing them. While essential, its size grows with each token, potentially increasing memory access times, especially for long contexts.
📌 Key Idea: Traditional LLM inference is a sequential, token-by-token process, where each generated token requires a full forward pass through the model.
Introducing Multi-Token Prediction (MTP): A Paradigm Shift
Multi-Token Prediction (MTP) fundamentally challenges the one-token-at-a-time paradigm. Instead of predicting a single next token, an MTP-enabled model is designed to predict multiple subsequent tokens in a single forward pass. This is achieved through specific architectural modifications within the transformer blocks themselves.
Core Concept: Parallel Prediction within a Single Pass
The goal of MTP is to reduce the number of sequential inference steps. If a model can predict K tokens in one pass instead of one, the effective tokens-per-second can theoretically increase by a factor of K (minus overheads).
Unlike simple N-gram models that statistically predict sequences, MTP leverages the full contextual understanding of the transformer architecture to generate a sequence of logits for K future tokens, all conditioned on the input.
The Problem It Solves
MTP directly tackles the sequential bottleneck of auto-regressive generation. By reducing the number of full model forward passes needed to produce a given amount of text, it significantly improves generation speed, especially for local inference where latency is often dominated by the per-pass computational cost.
MTP vs. Speculative Decoding: A Crucial Distinction
It’s easy to confuse MTP with speculative decoding, as both aim to speed up token generation. However, their mechanisms are distinct.
Speculative Decoding
Speculative decoding uses a smaller, faster “draft model” to speculatively generate a sequence of K tokens. The main, larger model then verifies these K tokens in a single, parallel forward pass.
- Draft Generation: A small, fast draft model generates
Kcandidate tokens. - Main Model Verification: The main LLM processes the original prompt + the
Kdraft tokens in one forward pass. - Validation: The main model’s output logits for each of the
Kpositions are compared against the draft tokens.- If a draft token matches the main model’s prediction, it’s accepted.
- If it doesn’t match, the sequence is truncated at the first mismatch, and the main model generates the correct token from that point onward.
- Fallback: If a mismatch occurs, the main model takes over, and the process potentially restarts with a new draft.
🧠 Important: Speculative decoding requires two models (a draft and a main model) and involves a verification step that can lead to rollbacks if drafts are incorrect.
Multi-Token Prediction (MTP)
MTP, on the other hand, is an inherent architectural feature of the main model itself. There is no separate draft model. The model is designed such that its forward pass directly produces logits for K future tokens.
- Single Model, Single Pass: The MTP-enabled main model performs a single forward pass.
- Multi-Logit Output: This pass directly yields
Ksets of logits, corresponding to the probabilities forKsubsequent tokens. - Parallel Sampling:
Ktokens are sampled directly from theseKsets of logits. - Append and Repeat: The
Kgenerated tokens are appended to the sequence, and the process repeats.
Workflow Comparison
⚡ Quick Note: MTP simplifies the inference pipeline by embedding multi-token generation directly into the model’s architecture, removing the need for a separate draft model and verification loop.
Internal Architecture of MTP-Enabled LLMs
The key to MTP lies in modifying the transformer’s attention mechanism or output head to predict multiple tokens. While the exact implementation can vary between models, a common approach involves techniques like “Grouped-Query Attention (GQA)” or similar mechanisms that allow for more efficient processing of multiple output positions.
Modified Transformer Block
In a standard transformer, the output layer typically projects the final hidden state of the last token into a vocabulary-sized logit vector. For MTP, this needs to be extended.
Consider a simplified MTP mechanism where the model is structured to inherently predict K future tokens. This might involve:
- Extended Output Head: Instead of a single linear layer producing one logit vector, there could be
Kparallel linear layers, each designed to predict one of theKfuture tokens. However, this is less common as it impliesKseparate prediction pathways. - Sequence-to-Sequence Prediction: A more elegant solution is for the model’s final layers to output a sequence of
Khidden states, each corresponding to a future token position. TheseKhidden states are then independently projected toKlogit vectors. - Causal Masking for Parallelism: Within the attention mechanism, the causal mask is crucial. For MTP, the attention mechanism must be able to compute the representations for
Kfuture tokens in parallel while still respecting causality (i.e., a token can only attend to previous tokens, not future ones within theKsequence). This is often achieved by adjusting the causal mask to allow tokens within theKoutput window to attend to all preceding input tokens, but not to tokens ahead of their own position within theKwindow.
Data Flow for MTP
Let’s visualize the conceptual data flow within an MTP-enabled transformer block:
(Note: In practice, the “Hidden State for Token X (Future)” are often derived from a single extended output representation, rather than completely separate pathways, but conceptually they lead to distinct logit predictions.)
Step-by-Step Breakdown of MTP Inference
Let’s walk through the process of generating text using an MTP-enabled LLM:
- Initialization:
- The model receives an initial prompt.
- The KV cache is empty or contains pre-computed keys/values for the initial prompt.
- First MTP Pass:
- The entire prompt sequence is fed into the MTP-enabled LLM.
- The model performs a single forward pass.
- Internally, its modified architecture calculates the attention and feed-forward operations for the prompt, and then, based on the learned patterns, projects
Ksets of logits for the nextKtokens. - The output is
logits_1, logits_2, ..., logits_K.
- Parallel Sampling:
- From
logits_1,token_1is sampled. - From
logits_2,token_2is sampled. - …
- From
logits_K,token_Kis sampled. - This sampling happens effectively in parallel.
- From
- KV Cache Update:
- Crucially, the Key and Value (KV) states for the newly generated
Ktokens (token_1throughtoken_K) are computed during this single forward pass and appended to the KV cache. This is a significant efficiency gain, as it avoidsKseparate KV cache updates.
- Crucially, the Key and Value (KV) states for the newly generated
- Append and Repeat:
- The
Kgenerated tokens are appended to the current sequence. - The new, longer sequence (or just the last
Ktokens and the updated KV cache) becomes the input for the next MTP pass. - The process repeats from step 2 until the desired number of tokens is generated or an end-of-sequence token is produced.
- The
⚡ Real-world insight: Qwen2 models, for example, leverage techniques like group_size_rope within their RotaryEmbedding to enable efficient grouped attention, which is a key enabler for MTP-like behavior, allowing the model to compute multiple subsequent tokens more efficiently.
KV Cache Optimization and MTP
The KV cache is fundamental to efficient LLM inference. It stores the “key” and “value” vectors for each token in the context, preventing their recomputation in subsequent steps.
How MTP Enhances KV Cache Utilization
In traditional inference, after generating one token, its KV pair is computed and added to the cache. This happens N times for N tokens.
With MTP, when K tokens are predicted in a single pass:
- Batch KV Computation: The KV pairs for all
Knew tokens are computed simultaneously during that single forward pass. - Reduced Memory Access: Instead of
Kseparate memory writes/appends to the KV cache, there’s effectively one larger, contiguous write operation for theKnew KV pairs. This can lead to better memory bandwidth utilization. - Cohesive Context: The model inherently understands the relationship between these
Ktokens and computes their KV states in a way that respects their sequential dependency within theK-token window, while still being conditioned on the preceding context.
This improved KV cache efficiency is a major contributor to the higher TPS observed with MTP-enabled models.
Performance Characteristics, Trade-Offs, and llama.cpp Integration
MTP offers substantial performance gains, but it comes with its own set of considerations.
Tokens Per Second (TPS) Improvements
- Significant Throughput Boost: MTP can lead to 2x to 5x (or more, depending on
Kand model size) increases in TPS compared to traditional auto-regressive decoding. This is because the fixed overhead of a forward pass is amortized overKtokens instead of just one. - Reduced Latency: While the first token latency might remain similar (as it’s still a full forward pass), the time to generate subsequent batches of
Ktokens is drastically reduced, making the overall generation feel much faster.
Hardware Trade-offs
- Increased VRAM Usage (per pass): While the total VRAM for the model weights and KV cache remains the same, the intermediate activations during an MTP forward pass might be slightly larger as the model is simultaneously processing for
Koutput positions. This is generally minor compared to the overall model size. - Compute Intensity: MTP still requires significant compute power. The gains come from reducing sequential operations, not necessarily total FLOPs (Floating Point Operations). A powerful GPU or multi-core CPU is still essential for optimal performance.
- Memory Bandwidth Criticality: With multiple tokens being processed and their KV states being written, memory bandwidth becomes even more critical. Systems with high-bandwidth memory (HBM) on GPUs will see greater benefits.
llama.cpp Integration and Model Support
llama.cpp is a highly optimized C/C++ inference engine for LLMs, known for its efficiency on consumer hardware. It directly benefits from and supports models with MTP-like architectures.
- Architectural Support, Not a Flag: MTP is not typically an
llama.cppfeature you enable with a flag (like speculative decoding). Instead,llama.cpp’s robust GGUF loading and inference capabilities natively support models that are designed with MTP in mind. - Qwen and Gemma Support: Models like Qwen2 and Gemma are prime examples of MTP-capable architectures.
llama.cppincludes specific optimizations andggufextensions to correctly interpret and execute these models, fully leveraging their internal MTP mechanisms. For instance, Qwen2 models use agroup_size_ropeparameter in their configuration, which indicates how Rotary Positional Embeddings are applied in a grouped manner, facilitating MTP.llama.cppunderstands this and optimizes the inference accordingly.
A Concrete Working Example: Running an MTP-Enabled Model in llama.cpp
Since MTP is an architectural feature of the model itself rather than a user-configurable flag in llama.cpp (like --speculative), the “example” is simply running a model known to have MTP capabilities. llama.cpp handles the internal optimizations automatically.
Let’s assume you have an MTP-enabled model like Qwen2-7B-Instruct in GGUF format.
Setup
First, ensure you have llama.cpp built with GPU support (if available):
git clone https://github.com/ggerganov/llama.cpp.git
cd llama.cpp
make -j CXXFLAGS="-O3 -DNDEBUG" LLAMA_CUBLAS=1 # For CUDA GPU support
# Or for CPU only: make -j CXXFLAGS="-O3 -DNDEBUG"
Download a Qwen2 GGUF model (e.g., from Hugging Face, search for Qwen2-7B-Instruct-GGUF and choose a Q quantization). Place it in your llama.cpp/models directory.
Running the MTP-Enabled Model
When you run a model like Qwen2 with llama.cpp, the underlying MTP optimizations are automatically engaged by llama.cpp’s specialized handlers for that model architecture.
# Example: Running Qwen2-7B-Instruct with llama.cpp
# This command doesn't have a special MTP flag; MTP is inherent to the Qwen2 model architecture
# and llama.cpp optimizes for it automatically.
./main -m models/qwen2-7b-instruct.Q4_K_M.gguf \
-p "Explain the concept of Multi-Token Prediction (MTP) in LLMs and its benefits for local inference." \
-n 512 \
--temp 0.7 \
--top-p 0.9 \
--color \
--mirostat 2 5 0.1 # Example sampling parameters
In this example, llama.cpp will load the Qwen2 model, recognize its internal MTP-friendly architecture (e.g., group_size_rope for grouped attention), and execute its forward passes in an optimized manner that leverages the model’s ability to predict multiple tokens per step. The user simply observes faster generation speeds without needing to configure MTP explicitly.
Why MTP May Significantly Change Local AI and Coding Workflows
The performance boost from MTP has profound implications for how we interact with LLMs locally:
- Faster Iteration for Developers: For code generation, debugging, or documentation, waiting for a few tokens at a time breaks flow. MTP enables near real-time suggestions and completions, making local coding assistants truly productive.
- Responsive Local Chatbots: A conversational AI that responds instantly feels more natural and engaging. MTP brings this responsiveness to local setups, reducing reliance on cloud APIs for general chat.
- Enhanced Creative Workflows: Writers, designers, and researchers can generate ideas, drafts, or summaries much faster, accelerating their creative process without internet dependency.
- Enabling More Complex Local Agents: Agents that need to reason, plan, and execute multi-step tasks locally will benefit immensely from faster token generation, allowing them to complete tasks in a reasonable timeframe.
- Reduced Cloud Reliance: By making local inference significantly faster, MTP empowers users to keep sensitive data on their own machines and reduces the operational costs associated with API calls. This democratizes access to powerful AI.
Common Misconceptions and What Actually Happens
- Misconception 1: MTP is just batching.
- Reality: Batching involves processing multiple independent prompts simultaneously. MTP involves processing a single prompt to generate multiple sequential tokens in one logical step. While they both improve throughput, they address different bottlenecks.
- Misconception 2: MTP is the same as speculative decoding.
- Reality: As detailed earlier, MTP is an inherent architectural design of the main model, directly outputting multiple tokens. Speculative decoding uses a smaller, faster model to guess tokens, which the main model then validates. They are distinct approaches to speed optimization.
- Misconception 3: MTP makes any model fast.
- Reality: MTP requires the model to be specifically designed or fine-tuned to leverage this capability. It’s not a magic switch that can be flipped on any pre-existing LLM. Models like Qwen2 and Gemma have MTP-friendly architectures built-in.
Failure Modes: What Breaks, When, and Why
While MTP offers significant advantages, it’s not without potential challenges:
- Memory Exhaustion (VRAM/RAM): While MTP reduces the number of forward passes, each pass might have slightly higher peak memory usage for activations (especially if
Kis large) compared to a single-token pass. This can be a bottleneck on devices with limited memory. - Degraded Output Quality (Theoretical): If
K(the number of tokens predicted in one go) is set too high or if the model isn’t robustly trained for MTP, there’s a theoretical risk of reduced generation quality. Predicting many tokens at once might reduce the model’s ability to “self-correct” or adapt to very subtle contextual shifts that would normally be caught in a token-by-token loop. However, well-designed MTP models mitigate this through careful training. - Compatibility Issues: Older inference engines or those not specifically updated for MTP-enabled model architectures might not fully leverage the MTP capabilities, leading to sub-optimal performance. This is where projects like
llama.cppshine by actively supporting these new architectures. - Hardware Bottlenecks (Memory Bandwidth): Even with MTP, the process of loading model weights and writing KV cache entries remains. If the memory bandwidth of the hardware is insufficient, it can still become a bottleneck, limiting the achievable TPS gains.
Key Engineering Insights and the Future of Local Inference
MTP represents a critical step in the ongoing quest for efficient LLM inference. It highlights several key engineering insights:
- Architectural Innovation is Key: Performance gains aren’t just about bigger models or faster hardware; they increasingly come from fundamental architectural improvements within the models themselves.
- Software-Hardware Co-Design: Optimizations like MTP are most effective when the inference runtime (e.g.,
llama.cpp) is tightly integrated and optimized to leverage the model’s specific architectural features. - Democratization of AI: By making powerful LLMs run faster on consumer hardware, MTP accelerates the trend towards decentralized, private, and customizable AI experiences. This is particularly important for privacy-sensitive applications and regions with limited internet connectivity.
The future of local AI inference will likely see further innovations building upon MTP, potentially combining it with advanced quantization, efficient KV cache management, and even more sophisticated model architectures designed for parallel generation. This ongoing evolution will continue to push the boundaries of what’s possible on our personal devices.
References
llama.cppGitHub Repository: https://github.com/ggerganov/llama.cpp- Qwen2 Model Card (Hugging Face): https://huggingface.co/Qwen/Qwen2-7B-Instruct (Look for details on
group_size_ropeand related architectural specifics in the model’s configuration or research papers.) - Gemma Model Card (Hugging Face): https://huggingface.co/google/gemma-7b (Similar to Qwen, architectural details on efficient inference might be in their associated papers.)
- Speculative Decoding Papers: e.g., “Accelerating Large Language Model Inference with Speculative Decoding” by Google, or “Blockwise Parallel Decoding for Deep Autoregressive Models” which laid some groundwork.
Transparency Note
This explanation of Multi-Token Prediction (MTP) is based on the latest available information regarding LLM architectures and inference techniques as of May 2026. While the core concept of predicting multiple tokens in a single forward pass is established, specific implementations can vary between models (e.g., Qwen, Gemma) and inference engines (llama.cpp). The term “Multi-Token Prediction” is used here to broadly encompass architectural designs that enable such parallel generation, distinguishing it from speculative decoding. The llama.cpp example is conceptual, demonstrating how an MTP-enabled model would be run, with llama.cpp handling the underlying optimizations automatically.